A Detailed Execution Playbook for Technical Program Managers
Generative AI is no longer experimental.
Enterprises are allocating budget.
Product teams are embedding LLM features.
Executives expect measurable impact.
Yet many GenAI initiatives quietly stall before reaching production.
Not because the model is weak.
Not because the demo fails.
They fail because execution discipline is missing.
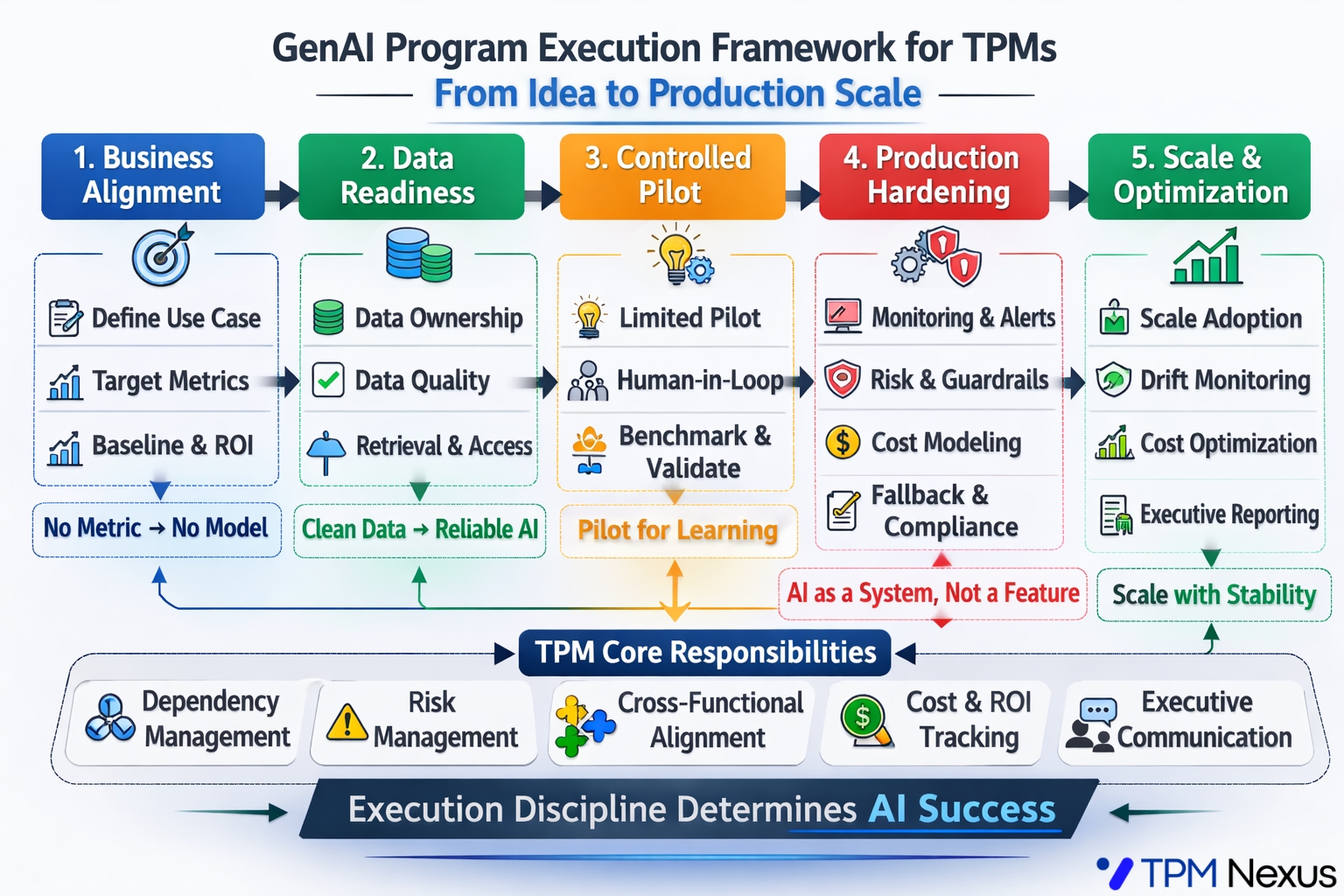
As Technical Program Managers, we operate in the execution layer. And in GenAI programs, that layer determines whether the initiative scales or collapses.
Let us break this down step by step with a real example.
A Running Example
AI Powered Customer Support Assistant
Imagine your company wants to deploy a GenAI assistant to:
- Auto draft responses for support tickets
- Reduce average handling time
- Improve resolution quality
Target metric:
- Reduce ticket resolution time by 30 percent
- Improve CSAT by 10 percent
Sounds straightforward.
Now let us walk through the execution lifecycle properly.
Phase 1. Business Alignment
What Most Teams Do
They say:
Let us integrate GPT into the support workflow.
What TPMs Should Do
Force clarity on:
- What ticket categories are in scope?
- What is current average resolution time?
- What is baseline CSAT?
- What cost savings are expected?
For example:
- Current resolution time. 18 hours
- Target resolution time. 12 hours
- Monthly ticket volume. 100,000
- Estimated cost per agent hour. X
Now the AI initiative is anchored to business value.
Without this, you are running an experiment, not a program.
Phase 2. Data Readiness Audit
This is where many programs silently break.
For our support assistant example:
Key questions:
- Where is historical ticket data stored?
- Is it labeled consistently?
- Are responses standardized or highly variable?
- Do we have structured metadata?
Example issue:
You discover:
- 40 percent of tickets lack proper category tagging
- Historical responses vary widely in tone and format
- Sensitive data appears in ticket text
If you push to model evaluation before fixing this, output quality will be unstable.
TPM Action Plan:
Create a three layer audit:
- Data Ownership
Who owns ticket schema, tagging, cleaning? - Data Quality
Percentage of usable labeled data? - Retrieval Feasibility
Can relevant historical tickets be retrieved under 500 ms?
GenAI success depends more on context quality than model selection.
Phase 3. Controlled Pilot
Now suppose data readiness is addressed.
The team builds a POC that:
- Suggests responses for 10 percent of tickets
- Allows agents to edit before sending
This is good.
But here is where execution discipline matters.
TPM Checklist:
- Define pilot cohort clearly
- Track acceptance rate of AI suggestions
- Measure editing time
- Log hallucination instances
- Track latency
Example metrics during pilot:
- Suggestion acceptance rate. 62 percent
- Average editing time reduction. 25 percent
- Hallucination rate. 3 percent
- Average latency. 1.2 seconds
This gives you signal, not applause.
Phase 4. Production Hardening
Most teams underestimate this phase.
Moving from 10 percent to 100 percent rollout changes risk exposure.
Now consider:
- 100,000 tickets per month
- API cost per 1,000 tokens
- Average tokens per request
- Peak traffic hours
Cost Modeling Example:
- 1 request uses 1,200 tokens
- Cost per 1,000 tokens. $X
- 100,000 tickets monthly
Suddenly your monthly API bill becomes material.
TPM Responsibilities Here:
- Build cost forecast for 6 months
- Define cost per resolved ticket
- Create budget guardrails
Additionally:
- Implement monitoring dashboard
- Define escalation for hallucinated critical responses
- Add human override fallback
Production AI must be treated like a distributed system.
Phase 5. Scale and Optimization
After stable production rollout:
Focus shifts to:
- Drift detection
- Quality degradation monitoring
- Prompt optimization
- Cost optimization
For example:
You notice:
- Acceptance rate drops from 62 percent to 48 percent after 3 months
Possible causes:
- Product updates changed ticket patterns
- New categories not covered in training
- Data drift
Without structured monitoring, degradation goes unnoticed.
TPMs must build reporting cadence:
- Weekly performance summary
- Monthly cost analysis
- Executive level risk summary
This is how GenAI becomes strategic capability, not temporary feature.
Where Most GenAI Programs Actually Fail
Based on patterns across teams, failures cluster in five areas:
- No measurable business anchor
- Weak data foundation
- No structured pilot metrics
- Missing cost forecast
- Poor executive communication on risk
Notice something important.
Model benchmarking is rarely the core failure.
Execution architecture is.
The TPM Advantage in the GenAI Era
GenAI introduces probabilistic systems into organizations used to deterministic software.
This increases:
- Cross functional complexity
- Risk surface area
- Governance requirements
- Cost unpredictability
TPMs who understand:
- Data dependencies
- AI lifecycle stages
- Risk communication
- Cost architecture
Will operate closer to strategy, not just delivery.
A Simple Mental Model for TPMs
Before approving any GenAI rollout, ask:
- What metric moves?
- Is data ready and owned?
- How are we measuring pilot success?
- What is cost at scale?
- What happens when the model is wrong?
If you cannot answer all five clearly, the program is not ready.
Final Thought
GenAI success is not about prompt creativity.
It is about disciplined execution across lifecycle stages.
The model might generate text.
But structure generates outcomes.
For TPMs, this is a career inflection point.
Those who master AI program execution will shape the next wave of product development.
Built for GenAI TPMs who own outcomes, not demos https://www.tpmnexus.pro




