Most AI discussions focus on models.
However, accuracy, benchmarks, and pricing per token do not reflect real execution.
In practice, these metrics look strong on paper.
But in production systems, they often fail to matter.
The real problem is execution under constraints.
The Problem with How We Evaluate AI Systems
Most teams evaluate AI tools based on:
- Model accuracy
- Benchmark scores
- Cost per token
These metrics are useful. However, they miss a critical question:
Can this system support real workflows without interruption?
In demos, everything is controlled.
However, in production, workflows are messy and unpredictable.
Therefore, the gap between demo performance and real execution becomes obvious.
What Actually Breaks in Real AI Workflows
In real usage, AI supports workflows, not just single prompts.
As a result, issues start appearing quickly:
- Sessions get interrupted
- Context is lost between steps
- Teams restart work frequently
- Prompts are rewritten
- Outputs become inconsistent
Because of this, a larger issue emerges:
Execution fragmentation
Work that should flow continuously gets split into multiple retries.
Token Limits. The Hidden Execution Bottleneck
Token limits are often treated as a technical detail.
However, in practice, they act as an execution constraint.
When limits are restrictive:
- Workflows cannot complete in one flow
- Context cannot be preserved
- Multi-step processes break
- Users adapt to the tool instead of the tool supporting them
As a result, productivity drops.
This does not happen because the model is weak.
Instead, the system fails to sustain execution.
Why Cost Per Token Is a Misleading Metric
Many teams assume that lower cost per token means better efficiency.
However, this assumption breaks in real workflows.
Because:
- Interrupted sessions increase retries
- Retries increase total usage
- Context loss increases effort
- Rework increases delivery time
Therefore, even if the cost per token is low,
the cost per completed workflow becomes high.
AI from a TPM Perspective. Execution Over Capability
From a Technical Program Management perspective, AI is not just a tool.
Instead, it is part of a delivery system.
And delivery systems require:
- Continuity
- Reliability
- Predictability
If execution breaks, the system fails, regardless of model quality.
Therefore, the focus should shift from:
“What can the model do?”
to
“What can the system consistently deliver?”
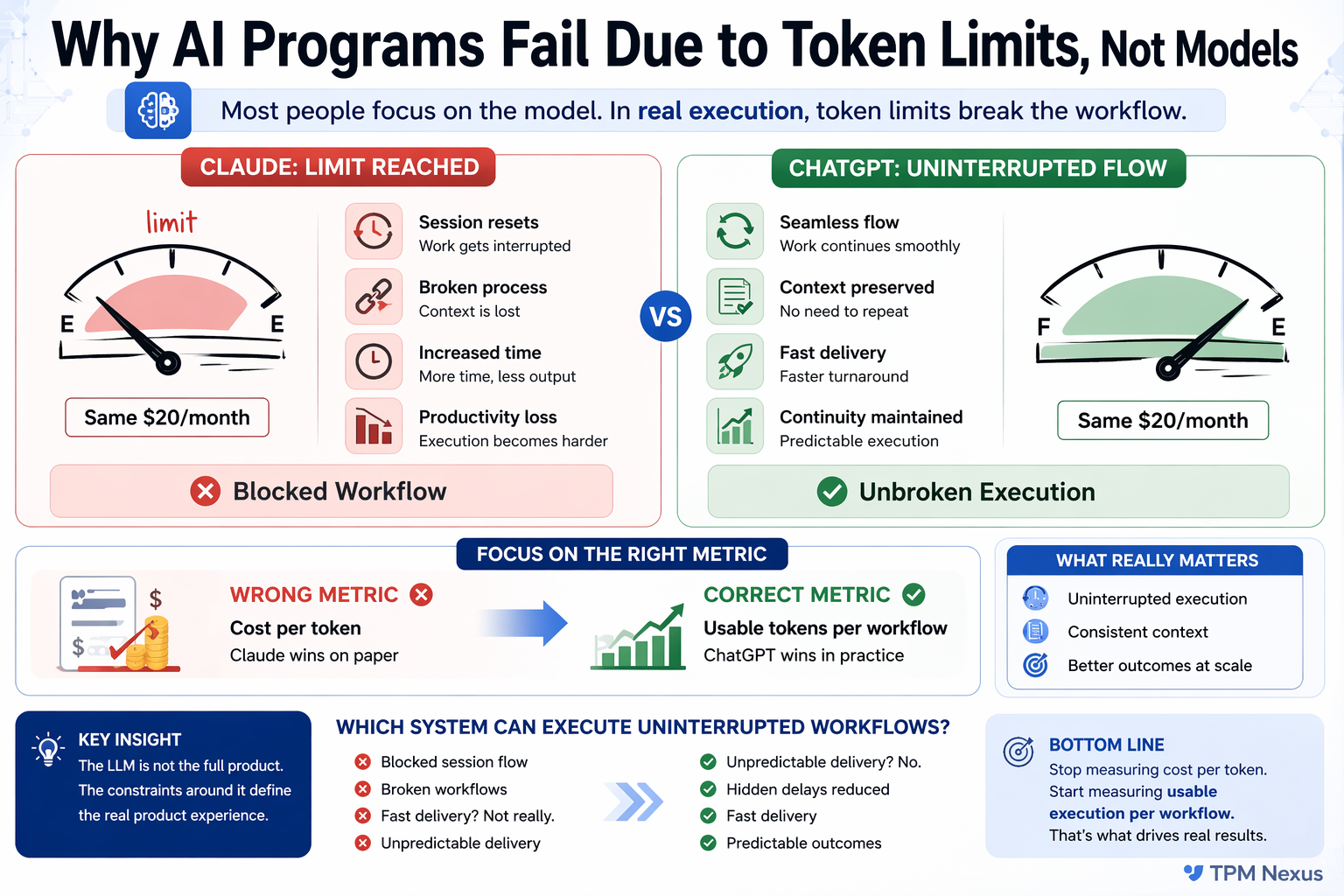
Case Insight. Same Cost, Different Outcomes
In one workflow, we evaluated two AI systems with similar pricing.
On paper, both appeared comparable.
However, in execution, the experience differed significantly.
With restrictive limits:
- Workflows broke into smaller chunks
- Context had to be rebuilt repeatedly
- Output consistency dropped
- Teams spent more time managing the tool
On the other hand, with flexible execution:
- End-to-end workflows ran smoothly
- Context was preserved
- Fewer retries were required
- Delivery became faster and predictable
Therefore, the difference was not model capability.
It was execution continuity.
Impact on Delivery and Teams
When execution becomes fragmented:
- Turnaround time increases
- Team efficiency drops
- Output quality becomes inconsistent
- Frustration increases
- Delivery becomes unpredictable
These are not model issues.
Instead, they are execution failures.
The Right Way to Evaluate AI Systems
We need to shift from:
Cost per token
to
Usable execution per workflow
This means asking:
- Can a workflow run end to end without interruption?
- Is context preserved across steps?
- How often does the user retry?
- Is output consistent across iterations?
- What is the actual effort required?
These questions reflect real usage.
Practical Checklist for AI Evaluation
Before selecting an AI system, evaluate:
- Can it support continuous workflows?
- Does it maintain context across steps?
- How frequently does execution break?
- What is the retry overhead?
- Is the output stable and predictable?
If these fail, model quality does not matter.
Key Lessons
- AI is part of a system, not a standalone capability
- Constraints define usability
- Execution matters more than model performance
- Workflow continuity drives productivity
Conclusion. Shift from Model Thinking to Execution Thinking
AI success does not come from choosing the best model.
Instead, it comes from designing systems that support uninterrupted execution.
The real differentiator is not intelligence.
It is usability at scale.
If the system breaks, the model does not matter.
If you are building or evaluating AI systems in production,
focus on execution, not just models.
Explore more practical frameworks here: www.tpmnexus.pro




